Thinking about Algorithmic problems II
Solving a programming problem that requires a custom algorithm can be broken in several steps which can be summarized in the creation of testing data, the implementation of a brutal force solution and the deeper study of the particular case which might reveal a smart trick to achieve an efficient solution.
In this posting we follow this approach applied to a problem that seems hard but after some thinking becomes very obvious and easy to solve.
The problem
Lets assume that we have an electronic device that in one unit of time can send a request and receive a response from a server; the possible responses are as follows:
- S: Success
- C: Corrupted data
- F: Failure to connect
Assuming 2 units of time the sequence our possible responses are as follows:
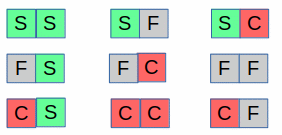
The software that controls our device will automatically stop in any one of the following conditions:
- Received two Failures at any time
- Received three consecutive corrupted data
Based on this definition the sequence for 2 units of time the possible valid signals are 8 :
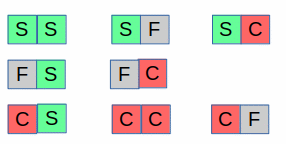
(Note that the FF sequence has been dropped)
To make our requirement cleaner assuming 3 units of time the sequence of valid signals (19) will be the following:
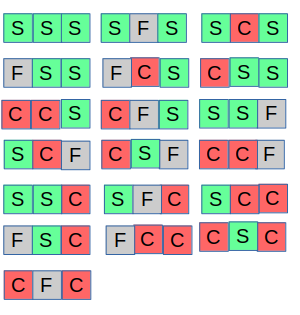
Note that the following 8 signals are dropped:
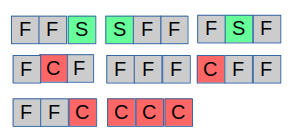
Our problem is the following:
For a given number of units of time calculate the count of all possible valid sequences of signals
The Brutal Solution
At this point you should pause and re-read the definition of the problem and try to digest it.
We already have the following test data:
| Units of time | Number of sequences |
|---|---|
| 1 | 3 |
| 2 | 8 |
| 3 | 19 |
Simply be noticing that each new sequence multiplies the existing signals by a factor of 3 for each Success, Failure and Corrupted message received we can easily code a brutal force solution which for each new time unit creates the new sequences and drops those ending with three corruptions or containing two failures at any point. Using our test data our brutal solution looks like the following:
def count_sequences_brutal(units_of_time):
sequences = ['S', 'F', 'C']
for i in range(1, units_of_time):
new_sequences = []
for sequence in sequences:
for c in 'SFC':
new_str = sequence + c
if 'CCC' in new_str or new_str.count('F') >= 2:
continue
new_sequences.append(new_str)
sequences = new_sequences
return len(sequences)
assert count_sequences_brutal(1) == 3
assert count_sequences_brutal(2) == 8
assert count_sequences_brutal(3) == 19
Now that we have a correct solution in place lets try to see how efficient it is in terms of performance as the number of time units is increasing:
Running the following code:
import timeit
import functools
for time_units in [2, 3, 6, 10, 20, 25]:
print(
'time_units:', time_units, 'duration:',
timeit.timeit(stmt=functools.partial(count_sequences_brutal, time_units), number=1)
)
We are getting the following output:
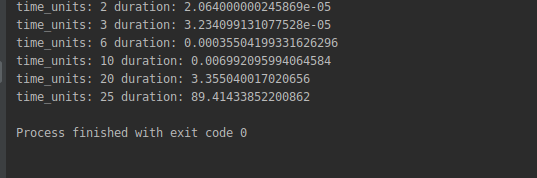
Note how quickly the running time grows; for 10 unit times 0.006 seconds are required but for 25 we are reaching more than 89 seconds!
Obviously our brutal force algorithm is terrible in terms in performance as it big O complexity is exponential. It still can be helpful for us since we create the following testing data that we will use later to test our efficient algorithm:
| Units of time | Number of sequences |
|---|---|
| 1 | 3 |
| 2 | 8 |
| 3 | 19 |
| 4 | 43 |
| 5 | 94 |
| 6 | 200 |
| 7 | 418 |
| 8 | 861 |
| 9 | 1753 |
| 10 | 3536 |
Analyzing the problem
At this point we have enough data and understanding of our problem so we can analyze it further and try to discover some hidden tricks that might allow us to come up with a smart algorithm that will solve it efficiently.
Thinking about our problem we can see that all of the following statements are all correct about a valid sequence:
- Ends with one of the letters S F C or CC
- Contains none or a single failure F
- Does not contain a CCC sub-sequence
Each iteration goes through all of the previous sequences and for each of them creates three new sequences appending the S F C to its end; as this happens some of them will be rejected as invalid due to the rules we have defined above as can be seen in this picture:
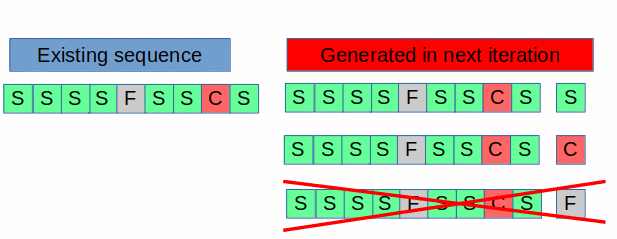
Having said this, we can express the count of valid sequences at any point by adding up the following counters:
| Counter Name | Description |
|---|---|
| FS | exactly one F, ending with S |
| FC | exactly one F, ending with C |
| FCC | exactly one F, ending with CC |
| S | no F, ending with S |
| C | no F, ending with C |
| CC | no F, ending with CC |
| F | ending with F |
If we could calculate these counters for each iteration using their previous value our solution could have become very fast as only one pass would be sufficient to solve the problem and this exactly what we will try to do next.
The algorithmic solution
After the first time unit our sequences look as follows:
![]()
with the following counters:
| Counter Name | Count> |
|---|---|
| FS | 0 |
| FC | 0 |
| FCC | 0 |
| S | 1 |
| C | 1 |
| CC | 0 |
| F | 1 |
Adding all counters we get 3 which matches the valid signals we have so far.
The second time unit will append each or the S F C to each of the existing sequences, creating 9 possible combinations.
Since we already have broken down the existing sequences based on the rules of the problem, instead of creating all the combinations we can now use the known information to increase all the available counters for each of the S F C.
The next received message will do the following:
Processing the S (success) case
The FS counter (has one Failure, ends with Success) becomes the total of the previous: FS, FC, FCC and F
The S counter (has no Failure, ends with Success) becomes the total of the previous: S, C, CC
Processing the C (corrupted message) case
The FC counter (has one Failure, ends with C) becomes the total of the previous: FS and F
The C counter (has no Failure, ends with C) becomes the previous: S
The FCC counter (has no Failure, ends with C) becomes the previous: FC
The CC counter (has no Failure, ends with C) becomes the previous: C
Processing the F (failure message) case
The F counter (ending with Failure) will become the previous: C, S, CC
an easier to visualize view of what is said above is the following:
| Counters sequence with length N | Calculated based on previous sequence |
|---|---|
| FS [n] | FS [n-1] + FC [n-1] + FCC [n-1] + F [n-1] |
| FC [n] | FS [n-1] + F [n-1] |
| FCC [n] | FC [n-1] |
| S [n] | S [n-1] + C [n-1] + CC [n-1] |
| C [n] | S [n-1] |
| CC [n] | C [n-1] |
| F [n] | C [n-1] + S [n-1] + CC [n-1] |
Manually applying these calculations for several iterations we are getting the following results:
| Counter | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| FS | 0 | 1 | 4 | 12 | 30 | 70 | 156 | 337 | 712 | 1479 |
| FC | 0 | 1 | 3 | 8 | 19 | 43 | 94 | 200 | 418 | 861 |
| FCC | 0 | 0 | 1 | 3 | 8 | 19 | 43 | 94 | 200 | 418 |
| S | 1 | 2 | 4 | 7 | 13 | 24 | 44 | 81 | 149 | 274 |
| C | 1 | 1 | 2 | 4 | 7 | 13 | 24 | 44 | 81 | 149 |
| CC | 0 | 1 | 1 | 2 | 4 | 7 | 13 | 24 | 44 | 81 |
| F | 1 | 2 | 4 | 7 | 13 | 24 | 44 | 81 | 149 | 274 |
| Totals | 3 | 8 | 19 | 43 | 94 | 200 | 418 | 861 | 1753 | 3536 |
Note that the bottom line of the above table contains the totals for each iteration; comparing them with we have gotten from the brutal solution we happily see that the results are matching so our algorithm is correct.
The code
Now that we have figured out the algorithm the next (and easiest) step is to to express it in code as can be seen here:
def count_sequences(N):
fs = 0
fc = 0
fcc = 0
s = 1
c = 1
cc = 0
f = 1
n = 1
while n < N:
fs, fc, fcc, s, c, cc, f = (
fs + fc + fcc + f,
fs + f,
fc,
s + c + cc,
s,
c,
c + s + cc
)
n += 1
return fs + fc + fcc + s + c + cc + f
We can also use the brutal solution to validate our implementation:
for i in range(1, 10):
assert count_sequences(i) == count_sequences_brutal(i)
Running the performance test as we did with the brutal solution previously:
for time_units in [2, 3, 6, 10, 20, 25, 10000]:
print(
'time_units:', time_units, 'duration:',
timeit.timeit(stmt=functools.partial(count_sequences, time_units), number=1)
)
gives us the following results:
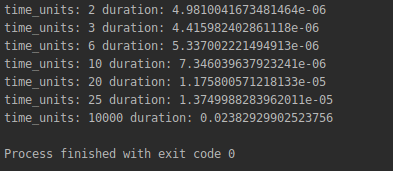
Comparing this output with what we have gotten before proves that now we have an extremely much faster algorithm that can be used for a very large number of iteration without significant delays.
To be more precise the time complexity of our algorithm is linear (O(n)) while its space complexity is O(1) as we do not allocate any additional memory to run it.
Conclusion
In this posting we had to deal with a problem whose obvious solution was very time consuming but after thinking a bit and understanding it better we were able to discover a “smart” trick to solve it efficiently; the same approach is applicable to many similar problems where the best solution lies in discovering some “hidden” properties that are not apparent from the first glance.
